Strange things can happen when working with characters. It is
important to understand why problems occur and what can be done about
them. This post is about getting Unicode to work at the Windows command
prompt (cmd.exe).
Topics:
- "Penny wise and pound foolish" - a character corruption example
- Character encodings and code pages
- Switching the Windows console to Windows-1252
- Unicode
- Unicode and the Windows console
- .Net and the Windows console
- Java and the Windows console
- End notes
This article requires your browser to be able to display
Unicode characters. E.g. я == я - if you
see a question mark there instead of a Cyrillic grapheme ( ), some of this article may not make as much
sense.
), some of this article may not make as much
sense.
£
"Penny wise and pound foolish" - a character corruption example
Lets look at the pound symbol
(£ - the currency symbol) on Windows XP configured with British
English regional settings. Most native English-speakers wouldn't regard
this as a particularly exotic character. If it isn't on your keyboard,
you can type it by holding down the right Alt key and
typing 0163 on the numeric keypad (assuming you're using a
Western European/US configured Windows). This may require some finger
gymnastics with custom function keys on laptops. Alternatively, you can
cut and paste it using the Windows Character Map
app (type charmap at the command prompt).

If we save this data using Notepad and dump it at the console,
the pound symbol is not printed. Instead, we get a lower case u
with acute (ú).
C:\demo>TYPE plaintext.txt abcú
If we copy the file to another machine (Ubuntu 8.10, British regional settings) and dump it to a console, we just get an error question mark symbol.
~$ cat plaintext.txt
abc?
However, when we open the file using the GNOME text editor (gedit), everything looks fine - the pound symbol appears.
Terminology: the big, bold name for the #
symbol is NUMBER SIGN (though it is also known as: pound sign; hash;
crosshatch; octothorpe; etc.). The big, bold name for £
is POUND SIGN (also known as: pound sterling; Irish punt; Italian lira;
Turkish lira; etc.).
Character encodings and code pages
To understand the problem, it is best to look at the hexadecimal form of the text file.
a b c £ 61 62 63 A3
Each of the programs is interpreting these values differently.
| Program | Character Encoding |
|---|---|
| Notepad | Using Windows-1252,
the default encoding for Windows when configured with Western
regional settings. Notepad's open.../save as...
dialogs have some character encoding options; the default is "ANSI",
which means Windows-1252 in this case. |
| Windows Command Prompt | Using code page 850, probably for backwards compatibility with old DOS programs. |
| Linux Terminal | Using UTF-8, one of the modern Unicode character encodings. This is the default encoding for the Ubuntu system. |
| gedit | Using ISO-8859-15,
an 8-bit character encoding very similar to Windows-1252.
Users can choose the encoding to use in the open.../save
as... dialogs. |
You can look up values on the 8bit charts by taking the hex value and matching the first digit to the left vertical column and the second digit to the top horizontal column. Note that the mappings in UTF-8 are not so simple; only a limited subset of characters can be represented in one byte; the remainder may need up to four bytes.
The character a has the same value in all these
mappings. This is a convenience mechanism used in the design of many
encodings (see the range of ASCII
printable characters) and is probably where the myth that there is such
a thing as "plain text" comes from. In the case of the pound character,
it does not share the same value in all encodings. It is represented by
a different value in some (e.g. Cp850; UTF-8) or may not be present
(e.g. Windows-1250;
Windows-1251).
Applications display the mappings for the encoding they use: A3
maps to ú in Cp850; the value A3 does
not map to a valid UTF-8 character, so an error symbol is displayed (a
question mark is often used for errors).
| Expected Character | Hex Value | Cp1252 | Cp850 | UTF-8 | ISO-8859-15 |
|---|---|---|---|---|---|
| a | 61 | a | a | a | a |
| £ | A3 | £ | ú | ? | £ |
Switching the Windows console to Windows-1252

Two steps are required to get the pound symbol to display in the Windows XP console when encoded as Windows-1252.
- Switch the console from the raster font to a Unicode TrueType font.
- Type
chcp 1252to switch code page.
C:\demo>chcp 1252 Active code page: 1252 C:\demo>TYPE plaintext.txt abc£
Unicode
Unicode is a single, unified character set that can describe any character. Prior to this, Windows developers juggled single-byte sets (like Windows-1252), double-byte sets (like the Korean code page 949) or used home grown solutions (like LMBCS). Despite standardisation on Unicode, we will be dealing with legacy character issues for a long time to come.
The Unicode character set assigns each character a unique value (see code charts). Encodings (e.g. UTF-8; UTF-16) describe how these values are mapped to byte values (using different bit values as a basis; e.g. 8bit; 16bit).
| Character | Grapheme | Unicode Value | Windows-1252 | Windows-949 | UTF-8 | UTF-16 | UTF-32 |
|---|---|---|---|---|---|---|---|
| LATIN SMALL LETTER A | a | 0061 | 61 | 61 | 61 | 00 61 | 00 00 00 61 |
| POUND SIGN | £ | 00A3 | A3 | 3F | C2, A3 | 00 A3 | 00 00 00 A3 |
| CYRILLIC SMALL LETTER YA | я | 044F | - | AC, F1 | D1, 8F | 04 4F | 00 00 04 4F |
| HALFWIDTH KATAKANA LETTER NU | ヌ | FF87 | - | - | EF, BE, 87 | FF 87 | 00 00 FF 87 |
| HANGUL SYLLABLE KIYEOK A SSANGKIYEOK | 갂 | AC02 | - | 81, 41 | EA, B0, 82 | AC 02 | 00 00 AC 02 |
| CYPRIOT SYLLABLE U | 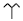 (𐠄) (𐠄) |
10804 | - | - | F0, 90, A0, 84 | D8 02, DC 04 | 00 01 08 04 |
| all values are hexadecimal; values are big-endian | |||||||
- UTF-8 is popular for text encoding because some binary values are common to many other character sets, particularly English/Latin characters. This is useful for working with apps that predate Unicode, or don't support it.
- Since the most useful characters can be described in 16bits,
it is a popular size for
chardata types (Java and .Net use UTF-16). - Even though it uses 16bits as a basis, UTF-16 can result in smaller files than UTF-8. It depends on the values being stored.
- Unicode introduces a host of new features and gotchas. For
example, some sequences of characters form combining
character sequences. The Devanagari
characters
0915(क),094D(्),0924(त) and0941(ु) combine to form the grapheme क्तु.
Unicode and the Windows console
From Wikipedia:
Under Windows NT and CE based versions of Windows, the screen buffer uses four bytes per character cell: two bytes for character code, two bytes for attributes. The character is then encoded as Unicode (UTF-16). For backward compatibility, the console APIs exist in two versions: Unicode and non-Unicode. The non-Unicode versions of APIs can use code page switching to extend the range of displayed characters (but only if TrueType fonts are used for the console window, thereby extending the range of codes available). Even UTF-8 is available as "code page 65001".
It is best to demonstrate by looking at the Win32 API. If you've never dealt with Windows programming, here are some of the salient points:
- Here,
charis 8 bits andwchar_tis 16 - "ANSI" and "Unicode" (or "wide") in Windows parlance. You won't often see strings expressed in these terms - they are often hidden behind types like LPCTSTR. - Functions often come in three flavours -
FunctionAfor ANSI (e.g.LPCSTR),FunctionWfor wide chars (e.g.LPCWSTR), and plainFunctionfor using macros to make it a compile time decision (e.g.LPCTSTR).
#include "windows.h"
void writeAnsiChars(HANDLE stdout)
{
// SetConsoleOutputCP(1252);
char *ansi_pound = "\xA3"; //A3 == pound character in Windows-1252
WriteConsoleA(stdout, ansi_pound, strlen(ansi_pound), NULL, NULL);
}
void writeUnicodeChars(HANDLE stdout)
{
wchar_t *arr[] =
{
L"\u00A3", //00A3 == pound character in UTF-16
L"\u044F", //044F == Cyrillic Ya in UTF-16
L"\r\n", //CRLF
0
};
for(int i=0; arr[i] != 0; i++)
{
WriteConsoleW(stdout, arr[i], wcslen(arr[i]), NULL, NULL);
}
}
int main()
{
HANDLE stdout = GetStdHandle(STD_OUTPUT_HANDLE);
if(INVALID_HANDLE_VALUE == stdout) return 1;
writeAnsiChars(stdout);
writeUnicodeChars(stdout);
return 0;
}
The above code uses two mechanisms to emit strings: the pound
symbol is printed using the ANSI API; then via the Unicode API with a
Cyrillic Ya (and a new line). You can uncomment the SetOutputConsoleCp
call to avoid having to use chcp beforehand. Here is the
code compiled with MinGW:
C:\demo>chcp Active code page: 1252 C:\demo>g++ printchars.cpp -o printchars.exe C:\demo>printchars.exe ££я
Alas, things still aren't perfect. The Lucida
Console font can display Cyrillic, but doesn't include the graphemes
required for many characters (e.g. HALFWIDTH KATAKANA LETTER NU - \uFF87).
| Lucida Console | |
|---|---|
| Unicode Ranges: | Basic Latin | Latin-1 Supplement | Latin Extended-A | Latin Extended-B | Greek and Coptic | Cyrillic, Cyrillic Supplementary | General Punctuation | Box Drawing | Block Elements |
| Code Pages: | 1252 Latin 1 | 1250 Latin 2: Eastern Europe | 1251 Cyrillic | 1253 Greek | 1254 Turkish | 869 IBM Greek | 866 MS-DOS Russian | 865 MS-DOS Nordic | 863 MS-DOS Canadian French | 861 MS-DOS Icelandic | 860 MS-DOS Portuguese | 857 IBM Turkish | 855 IBM Cyrillic; primarily Russian | 852 Latin 2 | 737 Greek; former 437 G | 850 WE/Latin 1 | 437 US |
Note: I didn't try using the Standard
C++ Library std::wstring with std::wcout - support isn't
there yet for MinGW (GCC version 3.4.2). I would probably have had
better luck with Visual
Studio. Take the claims of UTF-8 support in the Windows console with a
pinch of salt. Batch files won't run if you set the console to this
mode.
.Net and the Windows console
Calling the Unicode API is not what .Net does. The console needs to be set to UTF-8 to get Unicode support. C# code:
public class PrintCharsNet {
public static void Main(System.String[] args) {
System.Console.Write("\u00A3\u044F");
}
}
Note that the characters are denoted by Unicode
escape sequences (\u00A3 == £). This code (compiled
here with Mono) can
reliably print the pound symbol regardless of the code page the console
is set to. However, Ya requires a bigger character set.
C:\demo>mcs PrintCharsNet.cs C:\demo>chcp Active code page: 850 C:\demo>PrintCharsNet.exe £? C:\demo>chcp 1252 Active code page: 1252 C:\demo>PrintCharsNet.exe £? C:\demo>chcp 65001 Active code page: 65001 C:\demo>PrintCharsNet.exe £я
Emulating this behaviour in C++:
#include "windows.h"
int main()
{
HANDLE stdout = GetStdHandle(STD_OUTPUT_HANDLE);
if(INVALID_HANDLE_VALUE == stdout) return 1;
UINT codepage = GetConsoleOutputCP();
wchar_t *unicode = L"\u00A3\u044F";
int lenW = wcslen(unicode);
int lenA = WideCharToMultiByte(codepage, 0, unicode, lenW, 0, 0, NULL, NULL);
char *ansi = new char[lenA + 1];
WideCharToMultiByte(codepage, 0, unicode, lenW, ansi, lenA, NULL, NULL);
WriteFile(stdout, ansi, lenA, NULL, NULL);
delete[] ansi;
return 0;
}
Java and the Windows console
Java code to print the pound and Ya characters:
public class PrintCharsJava {
public static void main(String[] args) throws java.io.IOException {
System.out.print("\u00A3\u044F");
}
}
In Java, characters printed to System.out are
encoded using the default platform encoding, a property based on
operating system settings. For historical reasons, this is likely to be
a legacy encoding.
Charset encoding = Charset.defaultCharset(); |
On the test operating system, this is Cp1252 (list
of Java encoding aliases).
C:\demo>javac PrintCharsJava.java C:\demo>chcp Active code page: 850 C:\demo>java -cp . PrintCharsJava ú? C:\demo>chcp 1252 Active code page: 1252 C:\demo>java -cp . PrintCharsJava £? C:\demo>chcp 65001 Active code page: 65001 C:\demo>java -cp . PrintCharsJava ??
Emulating this behaviour with C++:
#include "windows.h"
int main()
{
HANDLE stdout = GetStdHandle(STD_OUTPUT_HANDLE);
if(INVALID_HANDLE_VALUE == stdout) return 1;
wchar_t *unicode = L"\u00A3\u044F";
int lenW = wcslen(unicode);
int lenA = WideCharToMultiByte(CP_ACP, 0, unicode, lenW, 0, 0, NULL, NULL);
char *ansi = new char[lenA + 1];
// CP_ACP == default system ANSI code page
WideCharToMultiByte(CP_ACP, 0, unicode, lenW, ansi, lenA, NULL, NULL);
WriteFile(stdout, ansi, lenA, NULL, NULL);
delete[] ansi;
return 0;
}
Ordinarily, the pound character will only display if the console is also using the default system encoding. It is possible to override the encoding:
C:\demo>chcp 65001 Active code page: 65001 C:\demo>java -Dfile.encoding=UTF-8 PrintCharsJava £яя
Setting file.encoding on the command line is not
recommended; doing so may adversely affect other encoding and I/O
operations. You can encode output programmatically too, but it doesn't
appear to be a very reliable approach - you'll note that, either way,
too many characters are written to the console (there should be only one
я).
//a programmatic approach
byte[] encoded = "\u00A3\u044F".getBytes("UTF-8");
System.out.write(encoded);
It isn't clear why too many characters appear in the output. Maybe it is a JRE bug; maybe I'm just missing something. It looks like native calls are the best way to get Unicode from Java to the Windows console.
End notes
This article only discusses output. Further reading is required to handle input.
Although this code was written on Windows XP, cursory testing on
the public Windows 7 Beta suggests that not much has changed for cmd.exe.
I'm being bad - I don't tell my compilers what encoding the
source files should be decoded as! I'm sticking to values I know are
common to many character encodings, including my default Windows-1252,
so I know they are going to be decoded correctly. But this is why I tend
to write \u00A3 in my code instead of the literal £.
Links:
- Code Page Identifiers (Windows)
- Code page tables supported by Windows
- SetConsoleOutputCP Only Effective with Unicode Fonts
- Necessary criteria for fonts to be available in a command window
- Why are console windows limited to Lucida Console and raster fonts?
- chcp can't do everything
In general, Raymond Chen's The Old New Thing and Michael Kaplan's Sorting it all Out are great blogs to search for Windows-related gems.
Versions used:
| Program | Version |
|---|---|
| Windows XP | Version 5.1.2600 |
| MinGW (GCC) | 5.1.3 (3.4.2) |
| Mono | 2.4 |
| .Net framework (runtime version reported) | 3.5 (1.1.4322.2407) |
| Java JDK | 1.6.0_05 |
| Java JRE | 1.6.0_13 |


Thank you so much. I have searched all day for this info. I was thinking that there was something wrong with my simple c++ program that needed to output german characters.
ReplyDeleteI looked all over for a way to tell the program that the characters I was using was latin-1. When I couldn't find anything, I switched to looking at codepages but that still didn't work. It came down to the rasterfont part, that I didn't know about. Geez, this character set thing is so screwed up....
Michael Kaplan has posted a round-up of articles related to cmd.exe and character handling in Myth busting in the console.
ReplyDeleteFantastic article!A great blog all in all!
ReplyDeleteHere is the equivelant example in Perl.
I can display a utf-16le encoded file just fine using type command in windows console, without calling chcp first. Why can't Java console i/o commands do the same?
ReplyDeleteTYPE is a shell command built into cmd.exe. Microsoft-generated text files are generally prefixed with a byte-order-mark. I expect cmd.exe detects this and uses WriteConsoleW (Unicode) or some internal equivalent to write the data to the device. cmd.exe is in a position to make more decisions about how to interpret its I/O.
ReplyDeleteI expect System.out maps onto STDOUT by default. You don't know what STDOUT is redirected to (a file, another program, etc.) It would be difficult to bake in any intelligent decision-making into System.out - it's just a byte stream with an encoder for the char methods. Choosing UTF-16 as the encoding would not help as cmd.exe doesn't accept UTF-16 via the standard I/O handles (and in any case, Windows 95's command.com probably didn't support Unicode so you're talking about breaking changes to behaviour.)
A more sensible candidate for adding Unicode console support would have been via the Console type. You can only acquire it under a terminal and it already interprets the console's legacy encodings. As to why it couldn't use the Unicode I/O methods - that's a question for the JDK maintainers.
Great article, but what are you doing if you want to use Hebrew, or any other local language which is not English?!?
ReplyDeleteUnfortunately, even if your system supporting the language, the command shell's properties showing only those 2 options (Lucida Console, Raster Font), both do not support Hebrew!
In this case you might need this article, which will help you in a preview step (changing the Registry and adding other fonts to the list)
http://ariely.info/Blog/tabid/83/EntryId/139/Windows-console-command-shell-Using-Local-Languages-En-US.aspx